1. Introduction
We consider the general problem of extracting areas in a high-dimensional data space where points that satisfy specific conditions are concentrated. Generally, as factors associated with a specific condition are often unknown, we use the most available factors and examine their relevance to a particular condition [
1]. However, the majority of the factors used are irrelevant or redundant, resulting in problems such as reduced accuracy of the analysis and increased analysis time [
1,
2]. Therefore, we are reducing the number of variables, a process called variable selection. Variable selection has various advantages, such as accuracy increase, analysis time reduction, and overfitting avoidance [
2,
3,
4]. Many models have been proposed for this variable selection and used in various fields [
4,
5,
6]. In recent years, machine learning models have been used to improve the accuracy of variable selection. For example, Genuer used random forests [
7] to select significant variables in high-dimensional classification problems [
8]. Grandvalet proposed a model that automatically performs relevance judgments and feature selection on support vector machines [
9] and showed its effectiveness in facial expression recognition tasks [
10]. However, machine learning models also have disadvantages; for example, generally their results are difficult to understand logically due to the complexity of these models and their black-box structure [
11,
12]. In addition, to the best of our knowledge, a general method for exhaustively extracting areas where the data that satisfy specific conditions are highly concentrated has not been established in the study of big data.
In this paper, we propose a new method based on a non-black-box model to solve this general problem. We use indicators calculated using the Bayesian method and Szymkiewicz-Simpson coefficient as evaluation measures for variable selection and extraction of pairs of variables, respectively. The Bayesian method is a data analysis method that uses existing information [
13,
14]. This point differs from the likelihood method and gives the advantage of more flexible model assumptions and facilitating statistical inference even for complex problems [
15,
16]. We use the Bayesian method, which is used in various fields, including ecology and seismology [
14,
15,
17,
18,
19], to construct the posterior distribution of a specific indicator. Then we use the lower limit of the confidence interval as a new indicator for the evaluation measure. As a basic tool of data analysis, we introduce the Szymkiewicz–Simpson coefficient, which quantitatively evaluates the degree of overlap between two sets [
20].
In this study, we analyze the factors that contribute to a firm’s high growth as an example of the application of this model. Firm growth is significant and attracts the attention of investors and banks [
21,
22]. Demirgüç-Kunt clarified that a firm’s growth is related to the financial and legal system [
23]. Baum extracted venture growth factors with structural equation modeling and data on 17 predictor variables [
24]. We analyze the factors of a firm’s growth using machine learning models in recent years. Van Witteloostuijn and Kolkman analyzed the factors that contribute to a firm’s growth using random forests [
25]. Among them, the phenomenon of high growth is heterogeneous, and Delmar showed that it can be classified into seven groups via cluster analysis [
26]. Coad forecasted high-growth firms with Lasso [
27], a machine learning model [
28]. We identify high-growth patterns using our model and verify them with Delmar’s and Coad’s results.
The remainder of this paper is organized as follows.
Section 2 explains the dataset and defines each firm’s growth rate in sales and high-growth firms.
Section 3 describes the mathematical basis used in this methodology and methods. We first determine the posterior distribution of the probability that a firm will grow high within a particular area using the Bayesian method and then define the existence probability of high-growth firms. We also provide proof of the formulas used in
Section 4 and the subsequent sections.
Section 4 describes step-by-step the results of the method and classifies the high-growth firms into 15 groups based on different factors. In
Section 5, we discuss the advantages, considerations, concerns, comparison with previous studies, and indicators of analysis. Finally,
Section 6 describes our results and the potential applications of our method.
2. Data
In this study, we use the corporate financial dataset provided by TEIKOKU DATABANK, Ltd. (TDB). In Japan, companies often ask a third-party corporate credit research organization to obtain information about a firm when they are looking for new business partners to expand sales or to check the business condition of existing business partners. TDB is one of the largest corporate credit research providers in Japan and has been providing corporate credit research for more than a century [
29]. In this study, we use 12 years of data from 2005 to 2016 with sales data existing for the next three years contained in this corporate financial dataset. The data include about 320,000 firms with
million data points. The first 10 years of the 12 years of data are used for the analysis, and the remaining 2 years are used for validation. Note that the dataset is not complete, and some financial items are missing in some firms. In such cases, we simply neglect missing items in our analysis. As a result, the number of firms in each financial item becomes equal to the total number of firms minus the number of missing data for the item.
We focus on the rate of increase in sales for each firm, which is defined by the following equation:
In this paper, we define high-growth firms as ones whose growth rate is in the top 1% of all firms in each analysis or verification data. Specifically, a high-growth firm has a growth rate of
times or higher for the analysis data and
times or higher for the validation data. We use our method to extract the conditions commonly satisfied by these high-growth firms in financial items. We exclude financial items that have a very strong correlation (correlation coefficient of higher than
) with the current sales used in the definition of growth rate in sales to avoid false correlations. We consider 156 financial items, such as the capital and current ratio in general.
To verify whether high-growth firms are dense not by coincidence, we randomly shuffle the 10 years of data from 2005 to 2014 for comparison. Namely, we create five sets of randomly shuffled data by using the command “shuffle” in Python for each of the 156 financial items with pseudorandom numbers generated by PCG64 [
30].
We apply our method explained in the following
Section 3 to the 10 years of real data and the five sets of randomly shuffled data.
4. Results
We define the abbreviated names for commonly used financial items, conditions, and units in
Table 1.
4.1. Extraction of One-Dimensional Areas for Each Financial Item
Step1 extracted 197 areas of 143 financial items. The top five areas with the highest existence probability of high-growth firms are presented in
Table 2.
The areas with the first and second highest existence probability of high-growth firms have a value of about
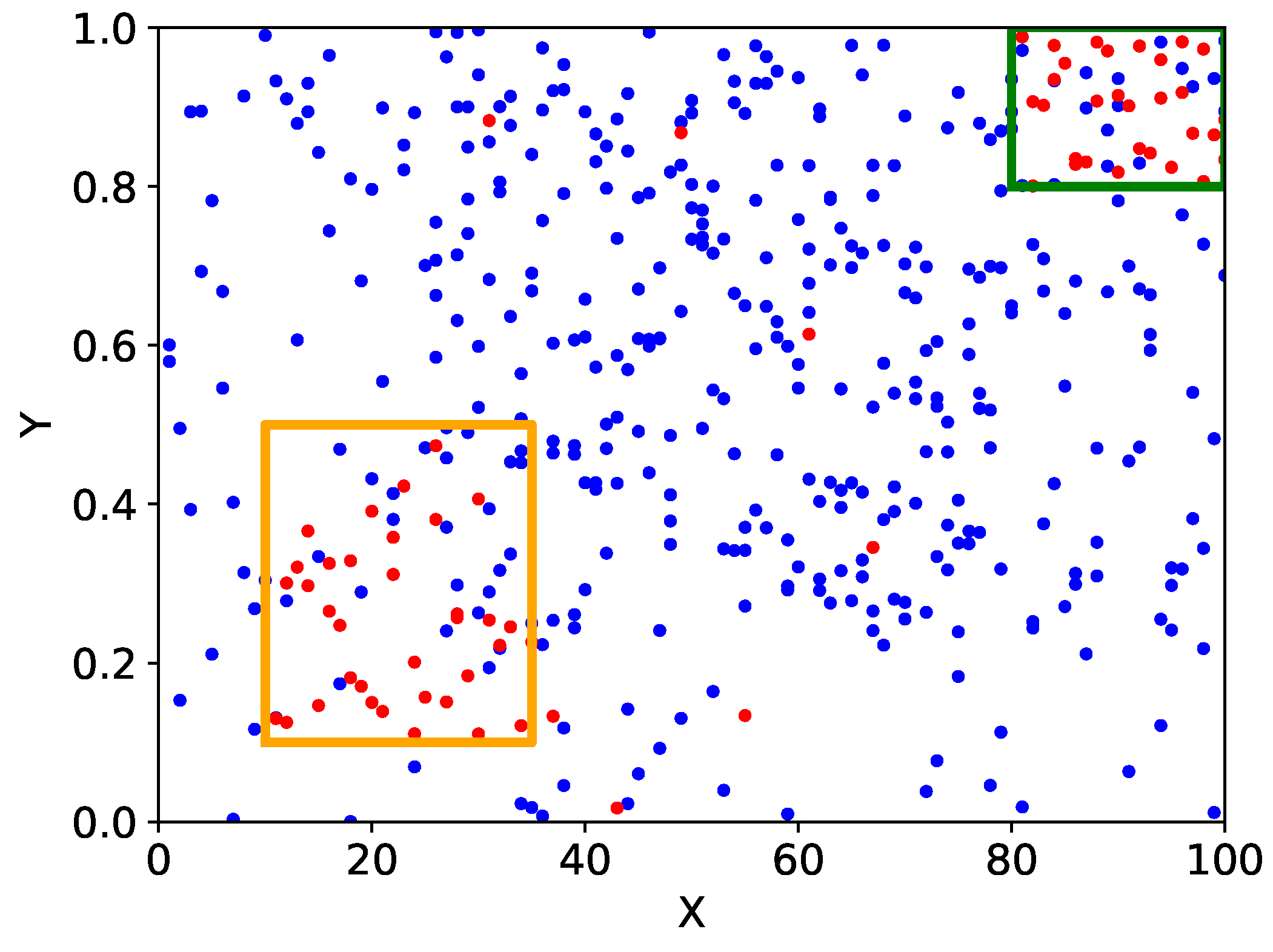
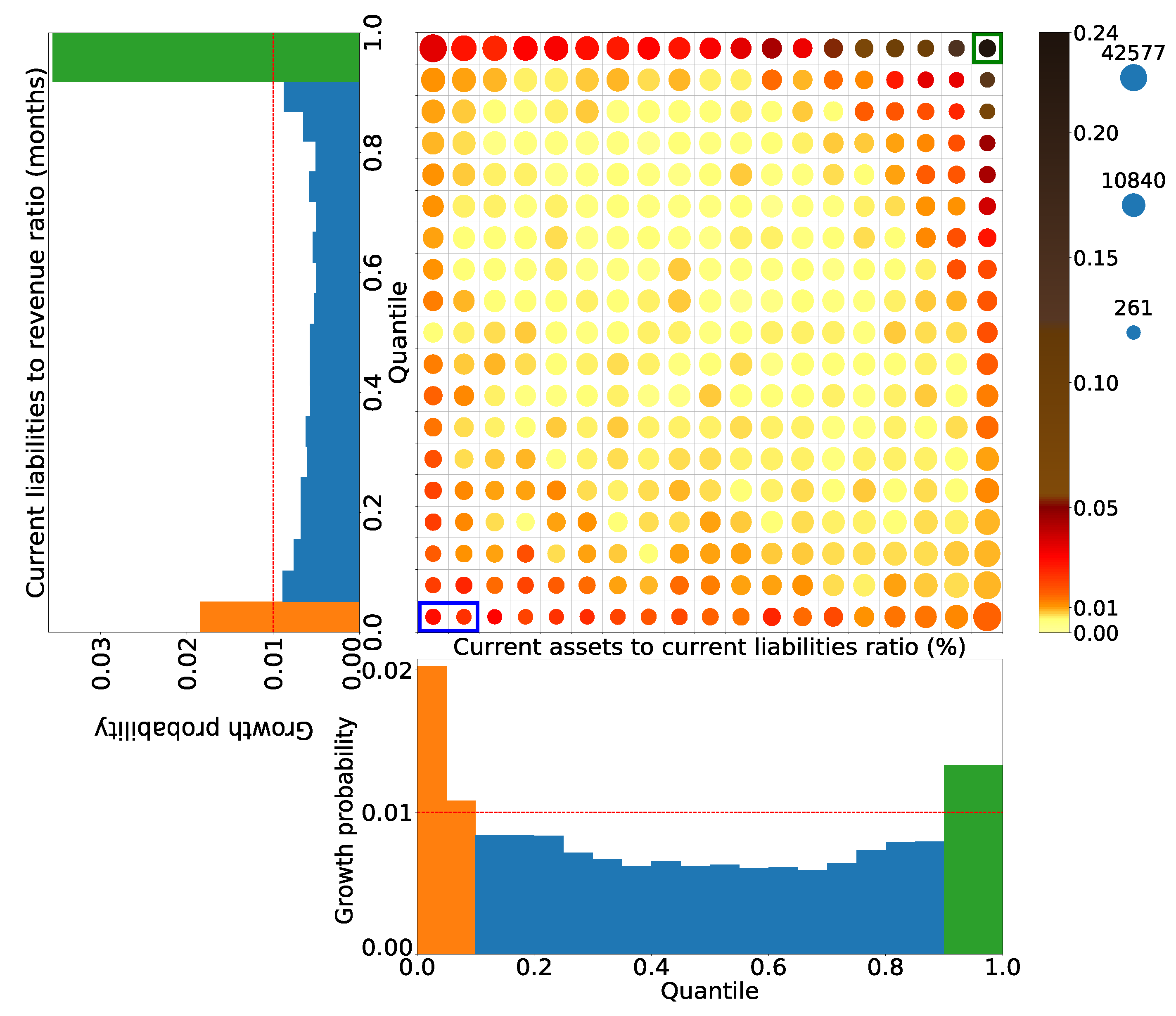
. This implies that they are more than four times more densely populated with high-growth firms than normal ones. Two areas were extracted for each of the 54 financial items. The distribution of the existence probability of high-growth firms and details of the areas extracted for one example of those financial items are presented in
Figure 3 and
Table 3.
These orange and green areas are where high-growth firms are about times more dense than normal ones. These areas are the two edges of the financial items, and it is thought that firms grow high due to different factors.
For validation, we performed the same one-dimensional extraction on five random data. We extracted 11, 11, 12, 13, and 13 areas, respectively. No multiple areas were extracted within a single financial item. The area with the highest existence of high-growth firms in these areas was about 1.08 times more dense than normal ones. These areas are used in Step2.
4.2. Reduction of Areas Containing Similar Data Points
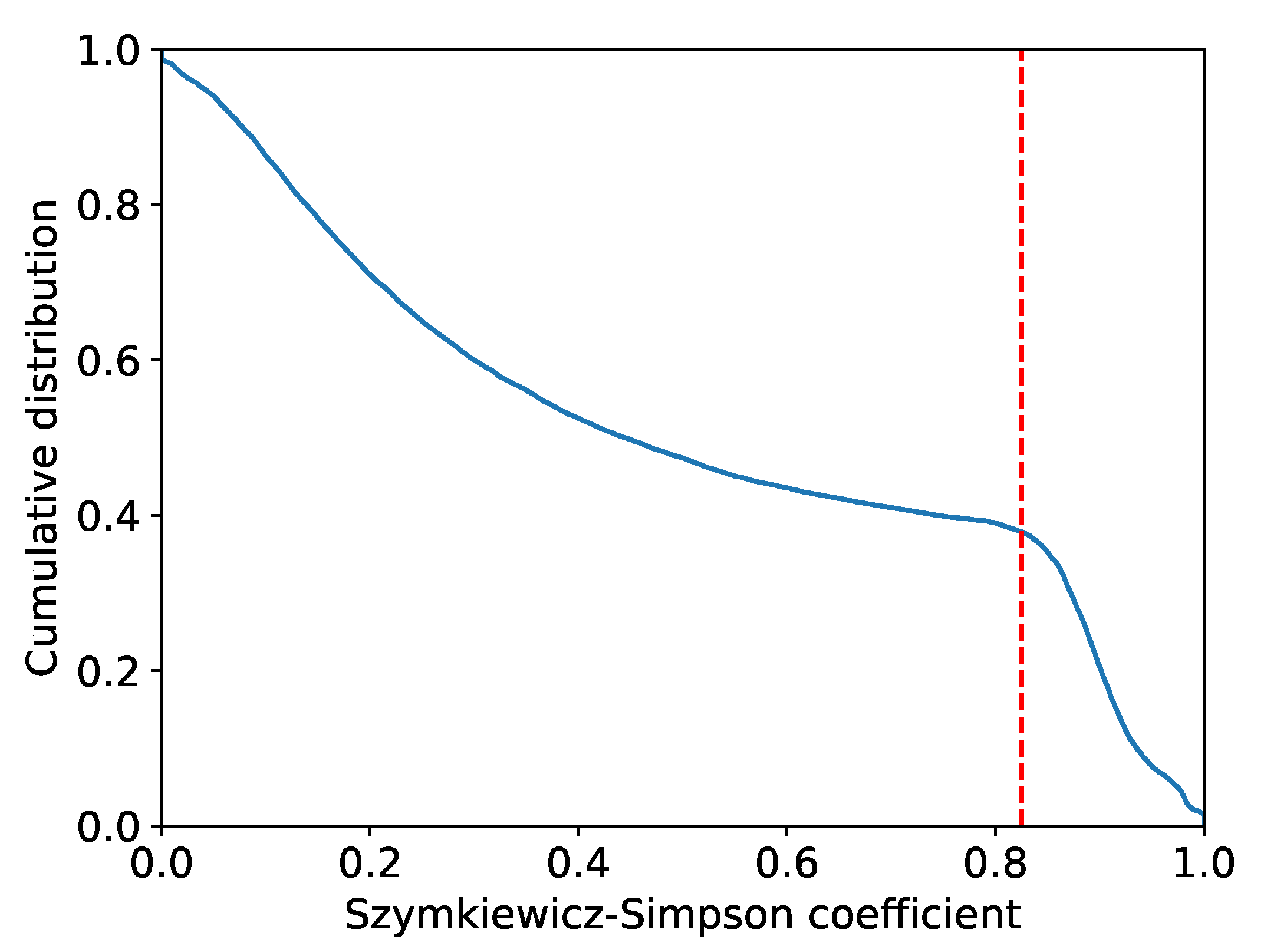
Similar areas were deleted in Step2 for the 197 areas of 143 financial items extracted in Step1. The result of calculating Equation (
9) for all combinations of the 197 areas is presented in
Figure 4.
Figure 4 shows that the cumulative distribution function changes its slope around when the value of the Szymkiewicz–Simpson coefficient is
. This value was used as the threshold value. In the combination of areas where the value of the Szymkiewicz–Simpson coefficient is greater than this value, the area with the smallest existence probability of high-growth firms was deleted. For example, the combination of an area with a turnover of current debt (months) of 7.44 or higher and an area with an increase/decrease in an investment of less than 0 (thousands of yen) resulted in a Szymkiewicz–Simpson coefficient value of 0.916. Therefore, we compared the existence probability of high-growth firms and removed the area with an investment volume of less than 0 (thousands of yen), which was a lower area. We finally extracted 67 areas of 51 financial items.
For the five random data, the highest Szymkiewicz–Simpson coefficient was about 0.24 in the combination obtained from the areas of financial items obtained in each. Considering that this is smaller than the threshold value of 0.825 in the data for analysis and that no similarity exists among the financial items and among the areas as the data were randomly shuffled, none of the areas were removed. The 11, 11, 12, 13, and 13 areas obtained in Step1 were used in Step3–Step5.
4.3. Extraction of Two-Dimensional Areas
The 67 areas of 51 financial items extracted in Step2 were used to extract the two-dimensional areas. We checked all possible combinations, and the top five two-dimensional areas with the highest existence probability of high-growth firms are presented in
Table 4.
In the two-dimensional area where the existence of high-growth firms is in the first and second places, high-growth firms are about 20 times more dense than normal ones.
Table 4 displays how many times the existence of high-growth firms is compared to when the two conditions are independent (Column Ratio), and these five areas are about five times as high. Therefore, some synergy must exist in the combination of these conditions.
Figure 5 presents the extracted two-dimensional area of the first rank.
The green box area at the right top in
Figure 5 is the area that satisfies the green areas in the turnover of current debt and the current ratio in the one-dimensional axes. It is 20 times more densely populated with high-growth firms than normal ones. It was also extracted as a two-dimensional area with the highest existence probability of high-growth firms. Meanwhile, the blue box area in
Figure 5 is the area that satisfies the orange areas in the turnover of the current debt and the current ratio in the one-dimensional axes. The existence probability of high-growth firms in this area is
. This value is lower than that of high-growth firms when the two conditions are independent, as calculated using Equation (
8). Therefore, this area was not extracted as a two-dimensional area.
We obtain 2211 two-dimensional areas using the 67 conditions used for the 67 areas extracted in Step2. Among them, we extracted 1036 areas that are more densely concentrated with high-growth firms than that when the conditions were independent.
For the five random data, we check whether high-growth firms are densely populated in the two-dimensional areas using the conditions used for the areas extracted in Step2. The number of areas extracted as areas where the existence probability of high-growth firms is higher than that of high-growth firms calculated using Equation (
8), under the condition that the two conditions are independent were 3, 4, 6, 7, and 9. Even in the area with the highest concentration of high-growing firms in any of the random data, the concentration of highest-growing firms is about 1.7 times the normal concentration. It was also about 1.5 times higher than when all conditions were independent, indicating no strong synergistic effect. These two-dimensional areas extracted as densely populated with high-growth firms in the random data are used in the analysis in step 4.
4.4. Extraction of Higher-Dimensional Areas
For the 1036 two-dimensional areas extracted in Step3, we extract 1036 high-dimensional areas by repeatedly adding the 67 conditions used in the 67 areas extracted in Step2. The top two high-dimensional areas that are extracted are presented in
Table 5 and
Table 6.
The existence probability of high-growth firms decreased when the 8th and 9th conditions were added to the areas in
Table 5 and
Table 6. Therefore, the areas with the 7th and 8th dimensions in
Table 5 and
Table 6 were extracted as areas with a high concentration of high-growth firms. The existence probability of high-growth firms in these high-dimensional areas is about 0.77. This implies that high-growth firms in these areas are about 77 times more dense than normal ones. They are also about 5–7 times higher than that when all conditions were independent. Therefore, we can assume that some synergistic effects occur in the combinations of these conditions. As shown in
Table 5 and
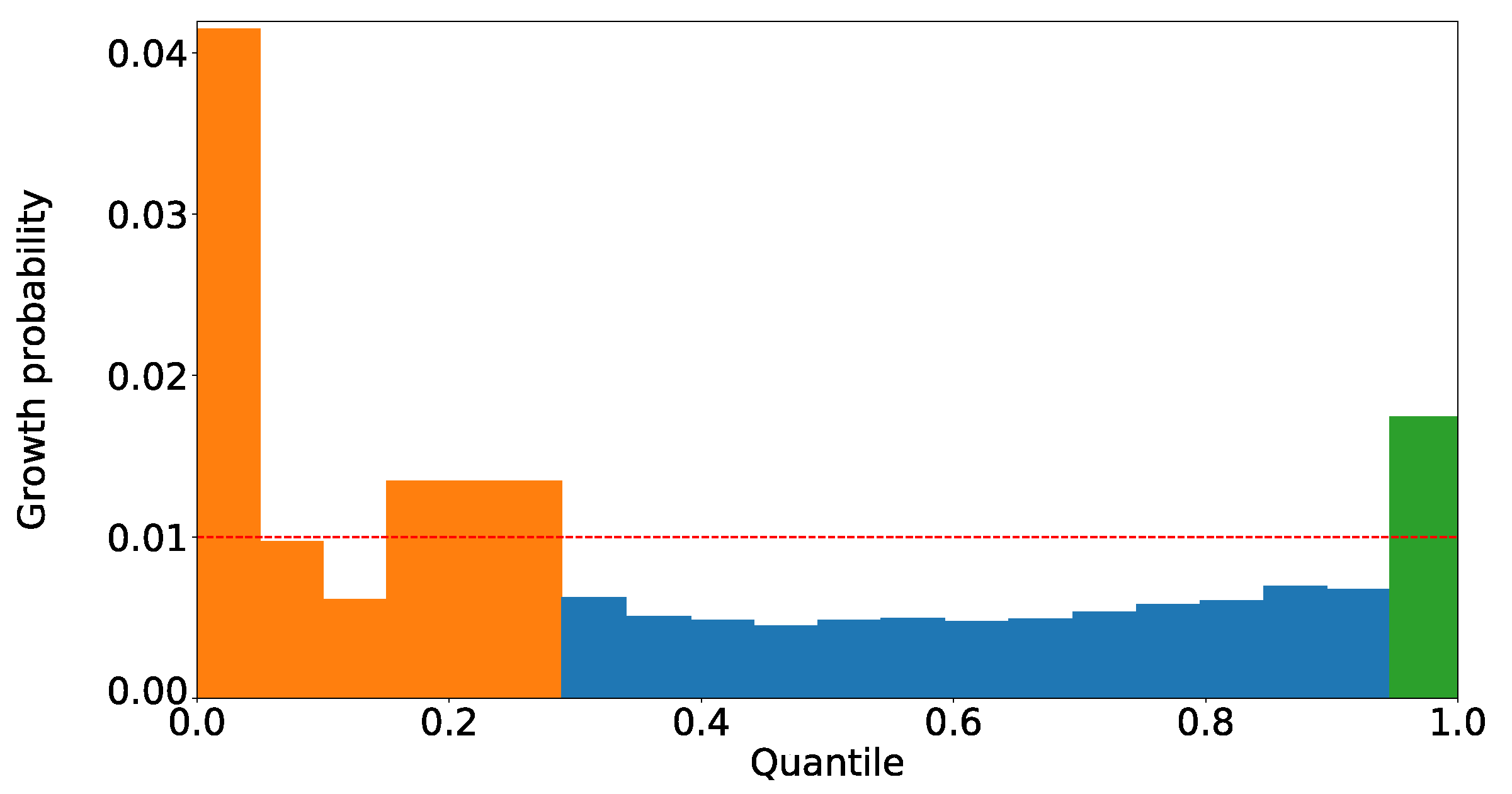
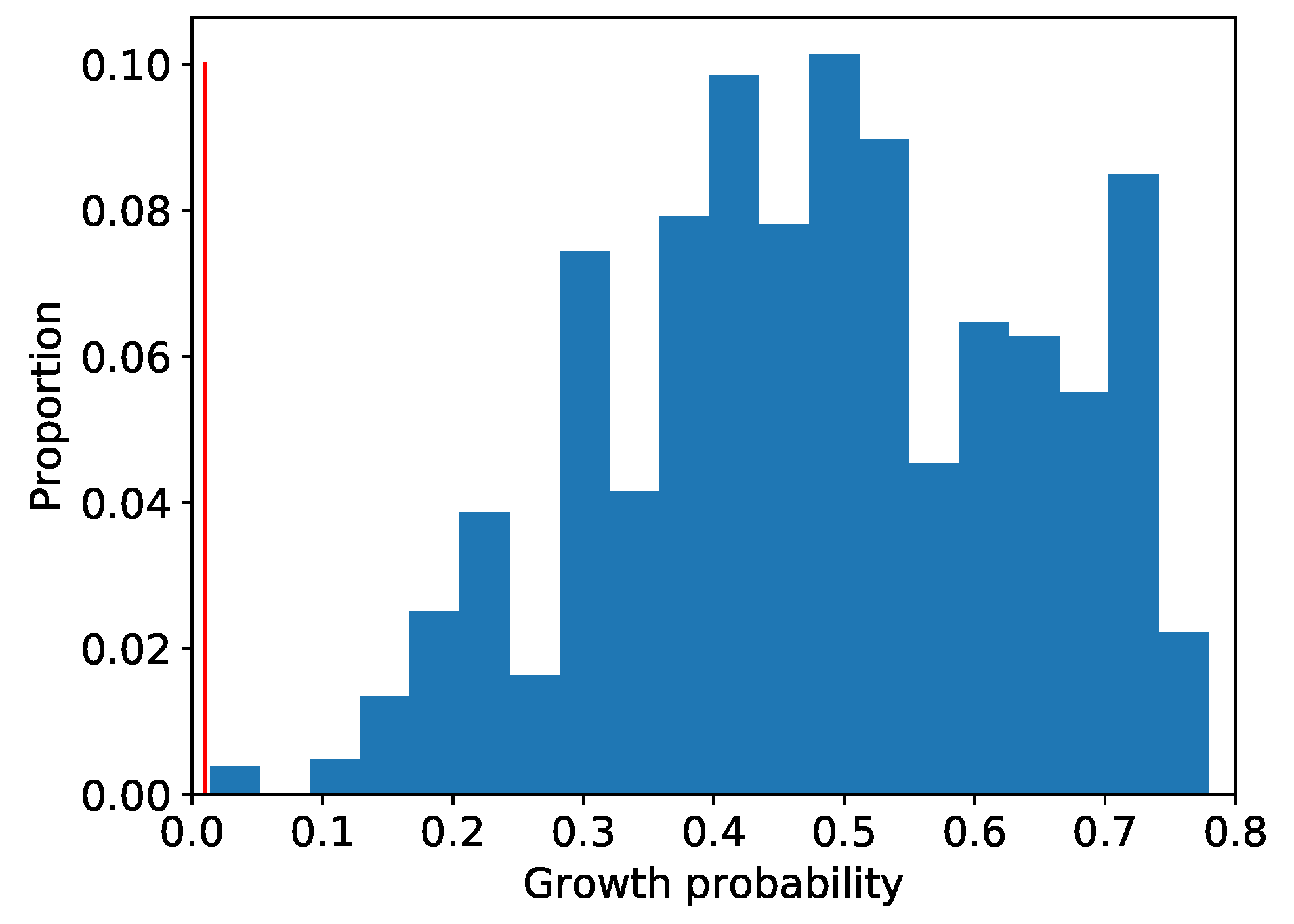
Table 6, we extract the high-dimensional areas from the 1036 two-dimensional areas obtained in Step3. The distribution of the existence probability of high-growth firms in the high-dimensional areas finally obtained is presented in
Figure 6.
As shown in
Figure 6, 90% of the 1036 high-dimensional areas were able to extract areas where the high-growth firms are dense at 30 times or higher than the normal density. We have also extracted four areas where the high-growth firms are dense at less than three times the normal density, and all of these areas were two-dimensional ones. Subsequently, areas with a small number of data are called local ones. These areas became localized at the two-dimensional level, and no further high-dimensional areas could be extracted. Our method searched the entire area exhaustively, and the extracted areas include the local ones.
For the 1036 high-dimensional areas obtained in these processes, we verified whether the existence probability of high-growth firms is also increased in the data for validation. The verification procedure is to add conditions in the same order as the conditions for the areas obtained in these processes until the existence probability of high-growth firms stops to increase. As specific examples, the results of the verification in the areas of
Table 5 and
Table 6 are presented in the
Table 7 and
Table 8, respectively.
In the validation for both areas, the existence probability of high-growth firms decreased when the 5th condition was added. Thus, we confirmed the robustness of the results up to the four-dimensional area in these areas. In this validation, the existence probability of high-growth firms in the one-dimensional area in both validation results was almost the same as that when the data for analysis were used. The existence probability of high-growth firms in the four-dimensional area when the data for verification were used was about 0.33 and 0.21 for
Table 7 and
Table 8, respectively. Although these values are lower than when using the data for analysis, we can assume that high-growth firms are concentrated at a high density, which cannot be considered coincidental. The reason for the lower existence probability of high-growth firms in the four-dimensional area, compared to that for analysis, and the failure of these areas to maintain robustness in the five-dimensional area can be attributed to the fact that the data for verification are one-fifth the number of data for analysis. That is the number of high-growth firms in the area at the four-dimensional area is about 15.7% and 14.0% in
Table 7 and
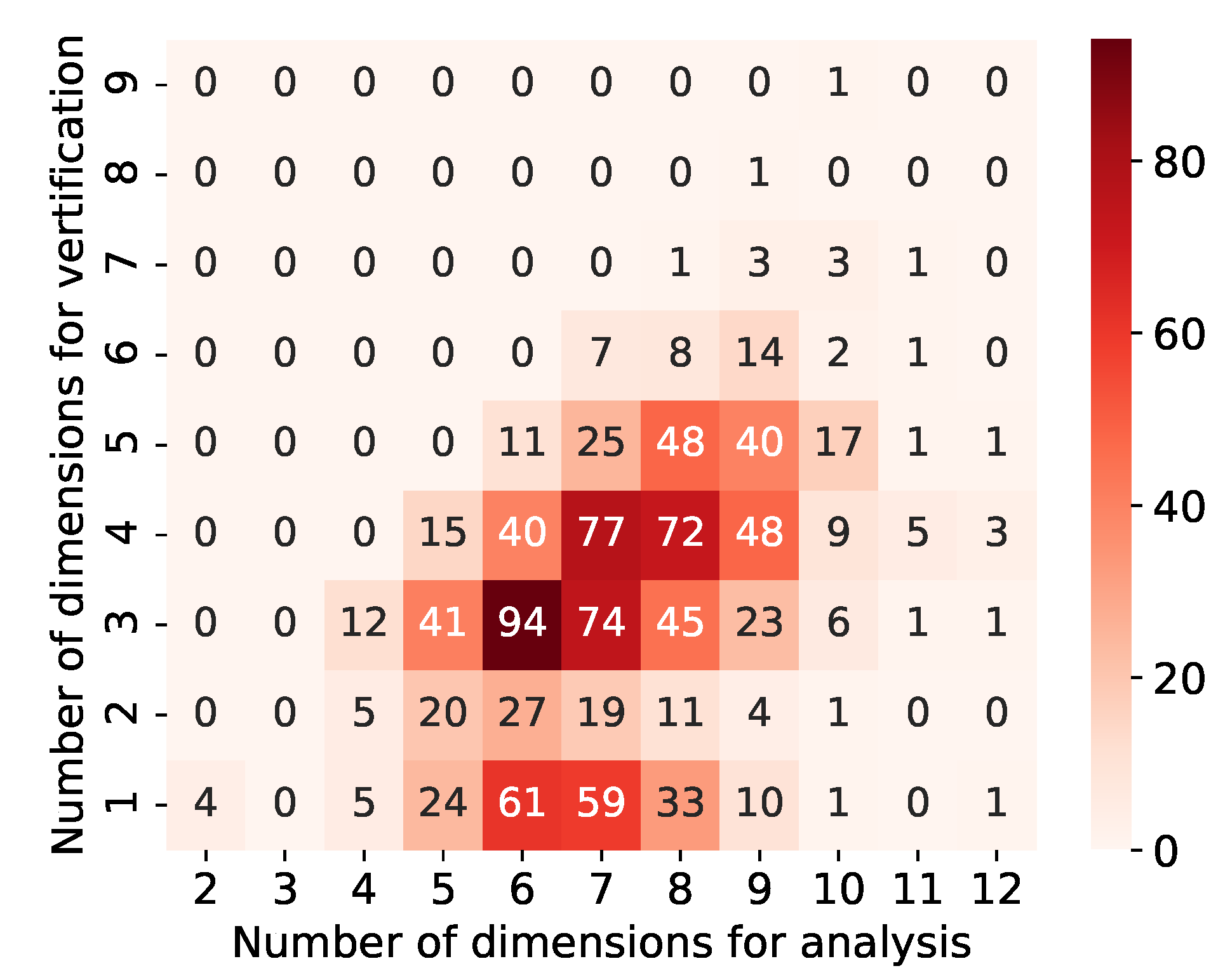
Table 8 for validation compared to that for analysis. Thus, the number of high-growth firms in the area is reduced, and the results are no longer stable and robust in high dimensions. The same verification was conducted for the remaining 1034 high-dimensional areas. The distribution of the number of dimensions for which the existence probability of high-growth firms was maximized in the data for analysis and verification was checked (
Figure 7).
The numbers in
Figure 7 represent the number of areas with each dimension in the analysis and validation data. For example, 77 with a vertical axis of 4 and a horizontal axis of 7 indicates that 77 areas have been extracted in seven-dimensional areas for analysis and verified to four-dimensional areas. Specifically, the area in
Table 5 is contained in 72 with a vertical axis of 4 and a horizontal axis of 8, and that in
Table 6 is contained in 77 with a vertical axis of 4 and a horizontal axis of 7 in
Figure 7.
Figure 7 presents that many high-dimensional areas of more than three dimensions are robust for verification. In addition, we can observe a relationship whereby the areas with higher dimensionality for analysis also maintain a higher dimensionality for validation. There was also a 10-dimensional area for which robustness was confirmed up to nine dimensions for verification. The details of this area are provided in
Table 9.
The area in
Table 9 is the area where the high-growth firms are about 70 times more densely populated than usual for the analysis. This area maintains robustness up to nine dimensions. In the data for verification, the high-growth firms are about 46 times denser than usual in this nine-dimensional area. We also extracted high-dimensional areas that can retain such robustness.
There are 165 areas where the increase in the existence probability of high-growth firms stops at one-dimensional areas for validation, despite that for analysis they are high-dimensional areas with six or more dimensions. In addition, in about half of the 1036 high-dimensional areas, an increase in the existence probability of high-growth firms stopped at three dimensions or less in the data for verification. Therefore, our method exhaustively searches the entire range and extracts local areas.
In the following, we focus on somewhat larger areas wherein the number of high-growth firms includes more than 1% (145 firms) of the total number of high-growth firms in the four-dimensional area in the data for analysis. There were 160 such high-dimensional areas. The areas in
Table 5 and
Table 9 are included in these 160 areas, but the area in
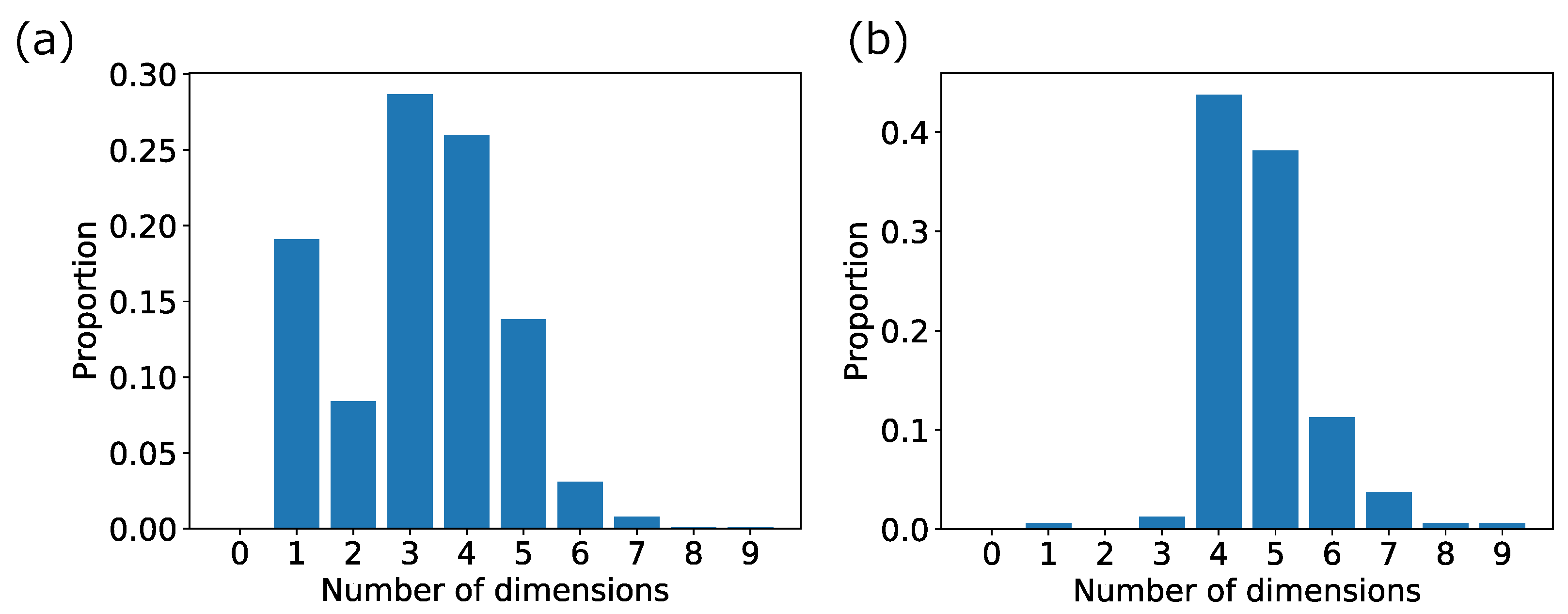
Table 6 is not. The distributions of the number of dimensions with the maximum existence probability of high-growth firms in the 1036 high-dimensional areas and the 160 non-local high-dimensional areas for verification are presented in
Figure 8a,b.
As shown in
Figure 8, the distribution of the number of dimensions that maximizes the existence probability of high-growth firms in the data for validation has changed significantly by narrowing down from 1036 high-dimensional areas to 160 high-dimensional areas, which include more than 145 high-growth firms. In most of the 160 areas, the number of dimensions in which the existence probability of high-growth firms is maximized in data for verification is four-dimensional or higher. Therefore, in these 160 areas, the robustness can be assumed to be up to four-dimensional. Focusing on these 160 areas, 1–3 in
Section 3.2.4 of the method are performed on these areas. The first corresponds to 40 areas, the second to zero areas, and the third to two areas. We finally focused on the 118 four-dimensional areas.
We extracted high-dimensional areas from each of the 29 two-dimensional areas extracted by the five random data. Consequently, we extracted seven three-dimensional areas and 22 two-dimensional areas. The results using the random data are presented in
Table 10.
Table 10 shows that we did not extract any high-dimensional areas in any random data. The area with the highest existence probability of high-growth firms among all the random data was the area where high-growth firms were 2.3 times more densely populated than usual. A comparison of the results with the data for analysis indicates that the high-growth firms are much more densely populated than in the random data. Considering that the random data extracted a maximum of only nine areas, the data for analysis, which extracted 1036 high-dimensional areas, showed that the high-growth firms were densely concentrated in many areas. Therefore, we can assume that strong relations exist between high-growing factors of firms and financial items.
4.5. Grouping
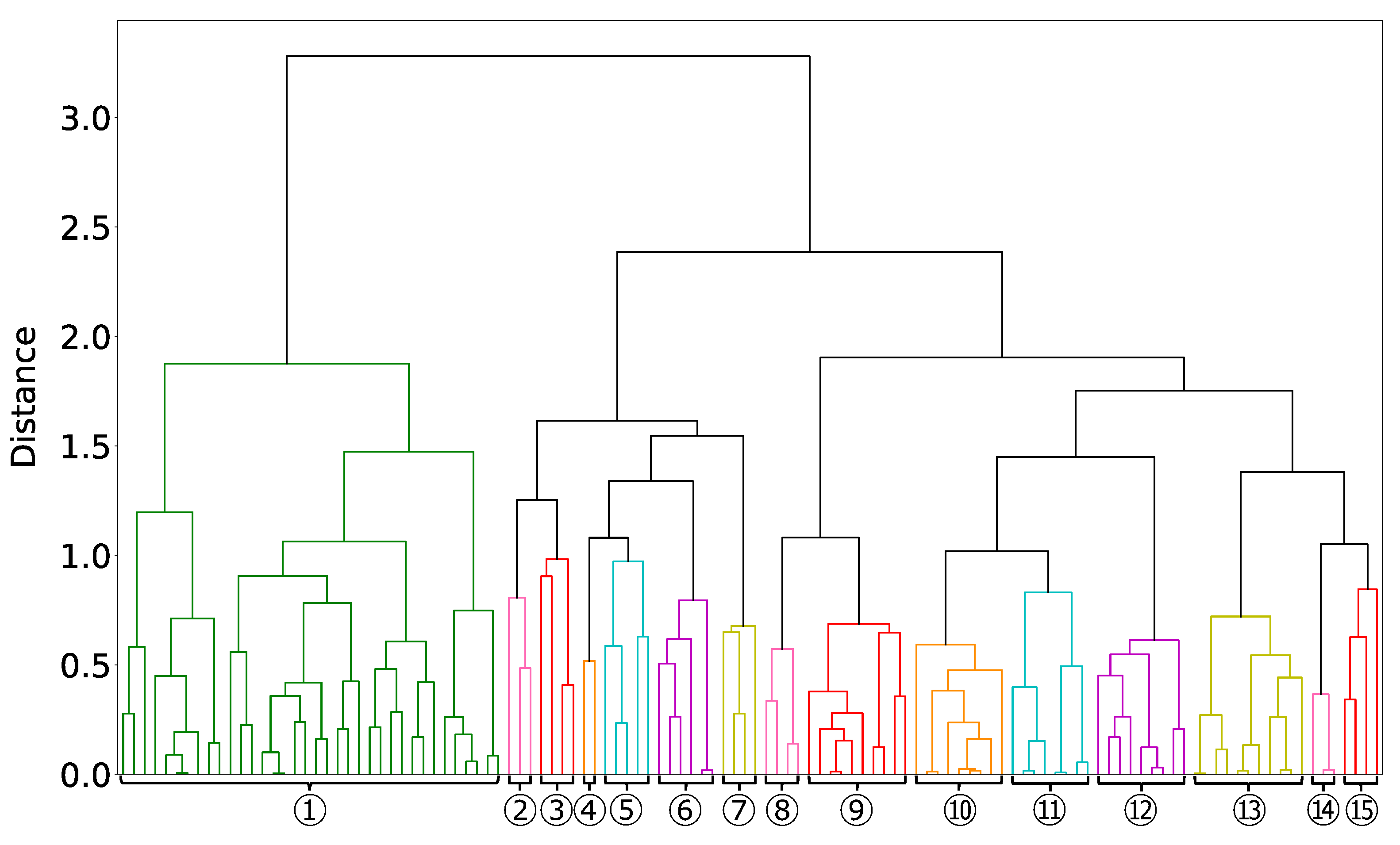
We define groups of the 118 four-dimensional areas selected in Step4 via hierarchical clustering with the ward method, Step5. The result is presented in
Figure 9.
We set the dissimilarity threshold used for grouping in
Figure 9 to a value that has a condition common to most of the grouped four-dimensional areas. Thus, the threshold was set to 1, except for the one group on the left, which is grouped because 34 of the 36 four-dimensional areas have the same condition. Finally, we divided the 118 four-dimensional areas into 15 groups. The conditions common to each of the 15 groups are presented in
Table 11. We focused on Groups ①, ②, ⑫, and ⑭, which are characteristic among the 15 groups.
Here, 34 of the 36 four-dimensional areas in Group ① have the common condition of small gross profit per capita (less than 2727). The small value indicates that the firms in these 34 areas have small sales and poor operating efficiency. The remaining two four-dimensional areas have the condition that the total capital (compared to all firms in the same industry) is small (smaller than three) and the turnover of total capital (month) is large (larger than ). The total capital (compared to all firms in the same industry) is the value evaluated by TDB and takes the value 0–10. The small value indicates that the total capital is very small compared to other firms in the same industry. The turnover of total capital (month) is the value of total capital divided by sales. Specifically, a large value of that indicates that sales are smaller than the total capital, given that the total capital is very small. Therefore, these two areas extract firms with very small sales and low efficiency. Therefore, the 36 four-dimensional areas in Group ① extract firms with small sales and low operating efficiency. These firms are considered to have improved their operations and increased their sales significantly after three years.
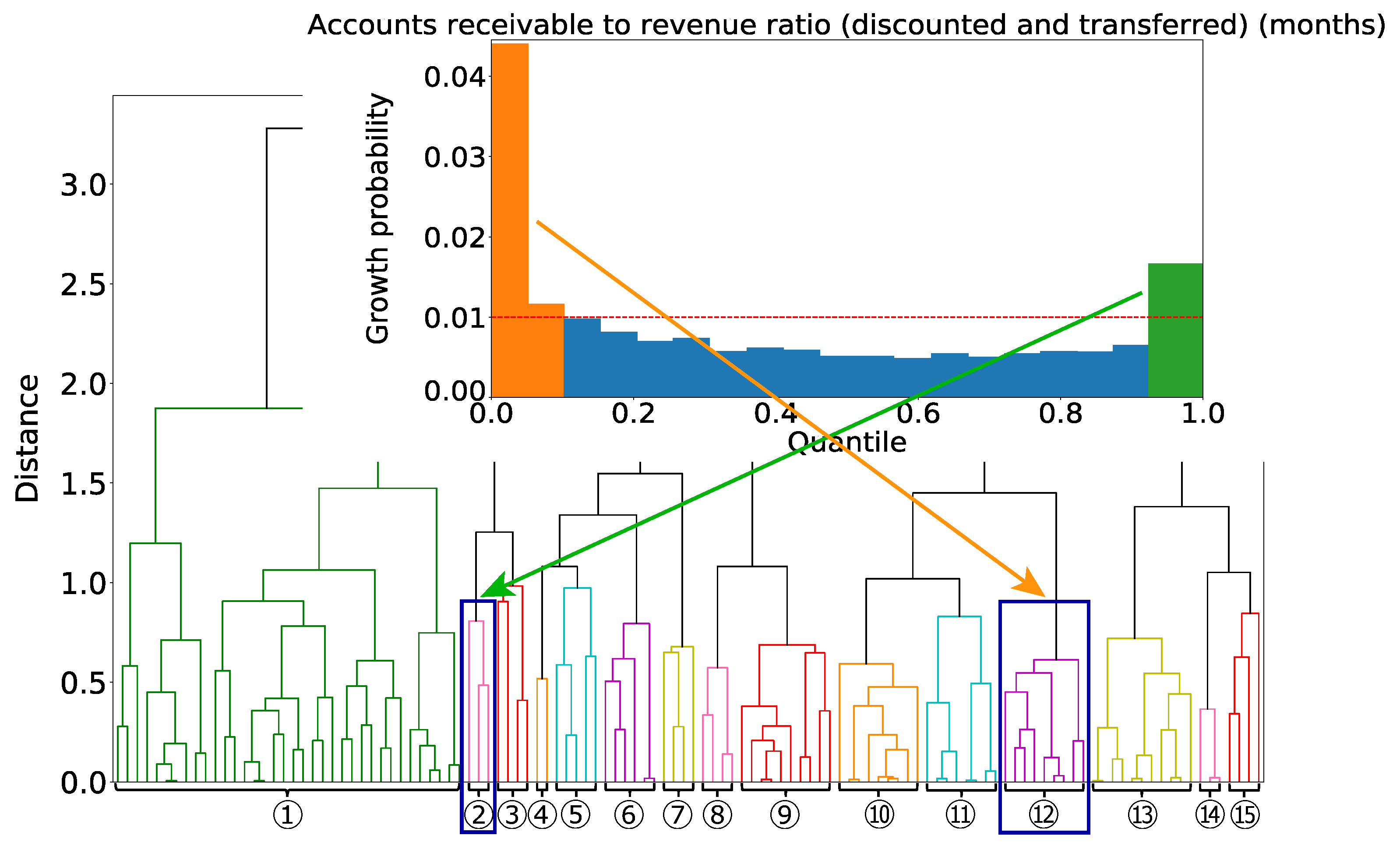
Next, we focus on Group ② and Group ⑫. These two groups are characterized by different areas of the single variable of the trade receivables (discounted and transferred) turnover periods (months) as shown in
Figure 10. Therefore, there is no firm that belongs to both Group ② and Group ⑫.
We consider what type of firms each group is extracting. Group ⑫ has in common the condition that the value of the trade receivables (discounted and transferred) turnover periods (months) is large. This large value implies that the ratio of trade receivables to sales is significant. That is, a firm takes a long time to convert its receivables into cash; thus, firms with insufficient working capital are extracted. In addition, the conditions that the ratio of ordinary income to total assets (industry comparison), turnover of total capital (industry comparison), and ratio of ordinary income to net sales (compared to all firms in the same industry) are bad are extracted together. Thus, we have extracted firms in Group ② that do not have enough working capital and whose profitability is worse. These firms could have improved their operations to afford working capital, which would have led to higher sales. Group ⑫ has in common the condition that the value of the trade receivables (discounted and transferred) turnover periods (months) is small. This small value indicates that, in contrast to Group ②, firms in Group ⑫ can afford working capital. In addition, the conditions that the ratio of ordinary income to total assets (industry comparison) and the ratio of ordinary income to net sales (compared to all firms in the same industry) are bad are extracted together. Therefore, firms in Group ⑫ with low profitability were able to use their surplus working capital to increase sales after three years.
Finally, we focused on Group ⑭. The shared conditions are presented in
Table 11. That is, these conditions include the absence of inventories, almost no non-operating income, and very large current assets. In Japan, current assets generally comprise of the following three elements [
32]:
Liquid assets: Short-term fixed deposits, securities, trade notes receivable, trade accounts receivable;
Inventories: Assets expected to sell on to earn revenue from sales of goods, products, etc.;
Others: Short-term loans receivable.
Short-term fixed deposits are those with a maturity of one year or less from the closing date. Securities are those with a maturity of one year or less or those held for the short term for trading purposes. Trade notes receivable are promissory notes received as payment for transactions with customers. Trade accounts receivable are accounts receivable from customers for business transactions. Liquid assets are the collective category of these four assets. Inventories are assets that decrease in quantity in the short term that are sold to earn revenue. Short-term loans receivable are loans with a maturity of one year or less from the closing date. Current assets are collectively liquid assets, inventories, and short-term loans receivable. Shared conditions indicate that Group ⑭ firms have large short-term fixed deposits, trade notes receivable, trade accounts receivable, and short-term loans receivable. Therefore, these firms have more assets that can be cashed in within a year. In addition, the conditions of small revenues, small gross profit per employee, and small ordinary income to revenue ratio are extracted together. Hence, we can assume that the firms in Group ⑭ are financially robust and have increased their operating efficiency by making capital investments, developing human resources, and increasing employment, resulting in a significant increase in sales after three years.
5. Discussion
We discussed the advantages of using our method. In this study, we first extracted one-dimensional areas, then deleted similar ones, and finally combined the conditions characterizing those areas to extract higher-dimensional crowded data satisfying specific rules. Our method has two advantages. The first is the possibility of extracting combinations of synergistic conditions. In the one-dimensional area extracted in this study, high-growth firms in the most densely populated area were about four times more densely populated than usual, and the average was about 1.7 times more densely populated than usual. However, by combining the conditions, our method can extract areas where the density of high-growth firms is much higher than when the conditions were independent. For example, the two-dimensional area with the highest existence probability of high-growth firms in
Table 4 is five times more densely populated with high-growth firms than that when the conditions are independent. Further, the high-dimensional area with the second highest existence probability of high-growth firms in
Table 6 is seven times more densely populated with high-growth firms than that when all conditions are independent. Thus, our method can exhaustively extract combinations that seem to have synergistic effects.
Second, our method can also extract local areas and robust high-dimensional ones. In this study, we focused on somewhat larger areas to analyze universal factors, but we also extracted local areas. For example, we extracted the areas on the left side in
Figure 6 where the existence probability of high-growth firms is lower than other extracted high-dimensional areas. We also extracted the high-dimensional areas at the bottom in
Figure 7 that can only validate up to low dimensions due to insufficient data for verification. Contrary to this study, we can use our method if we want to focus on local and specific cases, rather than universal ones. In addition, we can extract localized areas and areas with robustness. For example, we extracted the high-dimensional area with strong robustness (
Table 9). We can use our method when we want to focus on something universal, as in this study.
We discussed some of the considerations for this study. After the extraction of high-dimensional areas, we selected four dimensions as the number of dimensions that could withstand verification. First, we discussed regarding the extraction of high-dimension areas. Meanwhile, we extracted the areas of seven or more dimensions, in the data for verification, more than half of all extracted areas where the increase in the existence probability of high-growth firms stopped at three dimensions (see
Figure 8a). There are two reasons for this. The first one is that there were cases where the number of firms was small in the initially extracted areas because our method performed an exhaustive search that includes local areas. The second one is that the increase in the existence probability of high-growth firms tends to stop since the data for verification is one-fifth of the data for analysis in terms of the number of data. Therefore, if it is not a local area, we can increase the number of dimensions that allow verification by increasing the data for verification to about the same number as that for analysis. Second, we discussed the number of dimensions that we used. While increasing the number of dimensions that allow verification by increasing the data for verification, considering that the area tends to be localized is necessary. In this study, to focus on areas where firms universally tend to high growth, we focused on 160 four-dimensional ones where more than 1% of the total number of high-growth firms existed. Considering that we initially extracted 1036 high-dimensional areas, clearly that our method can easily extract localized areas. Therefore, determining to what dimensionality the results should be validated and used as universal results is necessary.
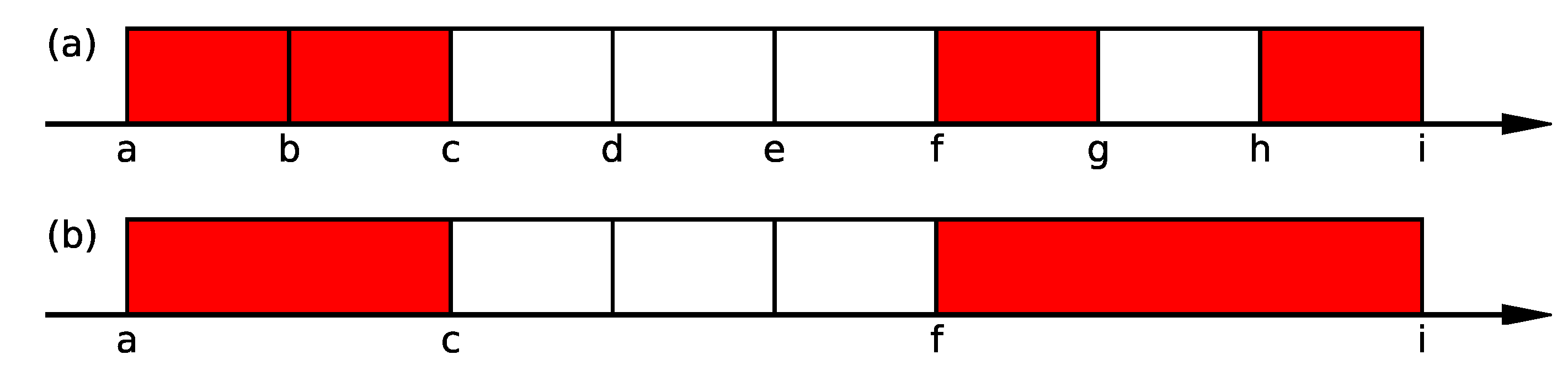
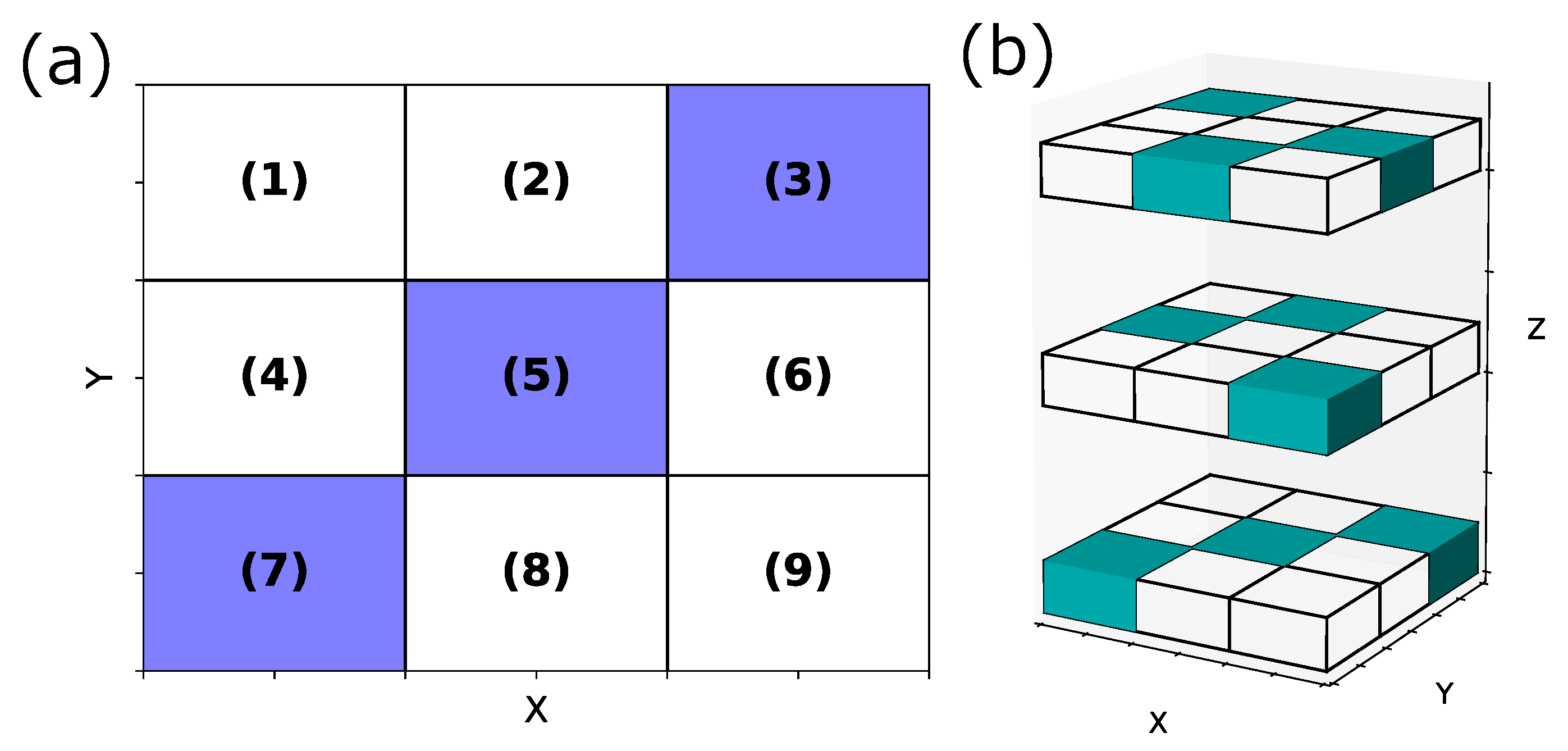
We also discussed some concerns when using our method. In this study, we first extracted one-dimensional areas, then deleted similar ones, and finally combined the conditions characterizing those areas to extract higher-dimensional crowded with data satisfying specific rules. However, if the densification occurs in the way shown in the following
Figure 11a,b, we miss dense areas.
In
Figure 11a,b, we divided each axis into three parts. Data satisfying specific conditions were densely populated in the colored areas in these figures. In
Figure 11a, the case of the missing dense area is when the existence probability of data satisfying specific conditions in areas (1)∼(3), (4)∼(6), and (7)∼(9) is equal. In this case, when projected onto the Y-axis, we cannot extract the area on the Y-axis. Thus, we cannot extract the two-dimensional areas (3), (5), and (7). We also consider the case where (1)∼(3) > (4)∼(6) > (7)∼(9) in terms of the density of data satisfying specific conditions between areas (1)∼(3), (4)∼(6) and (7) ∼(9). We consider areas (7)∼(9) as the areas where data satisfying the specified conditions are not dense on the Y-axis, and we cannot extract area (7). The possibility exists that a similar phenomenon may occur in the third dimension and beyond. In the case of
Figure 11b, as in the previous case, if the existence probability of data satisfying specific conditions is equal in the three divisions in any of the X-, Y-, and Z-axis directions, we cannot extract the colored areas in
Figure 11b.
We can consider a possible method to address this concern to start focusing on two or higher dimensions, rather than focusing on one dimension. In a pair that selects two from all variables, we can address this by dividing the area, calculating the existence probability of data satisfying specific conditions in each area, and extracting the areas with a higher density of data satisfying certain conditions than normal ones. In
Figure 11a, we can extract areas (3), (5), and (7) by calculating the existence probability of data satisfying specific conditions in each of areas (1)∼(9). In
Figure 11b, we can extract the colored areas by calculating the existence probability of data satisfying specific conditions in each of the 27 areas. Meanwhile, since this method requires considering all variable partitions and calculating the probability in each of them, we predicted a significant increase in computational cost. Specifically, we considered the case where we divide each financial item by 5% as in this study and searched in two dimensions, as shown in
Figure 11a, to avoid missing anything in dense areas. In this case, we divided each financial item by a maximum of 20 and considered the 12,090 combinations of selecting two from all 156 financial items. Therefore, it is necessary to calculate the existence probability of data satisfying specific conditions in a maximum of 400 areas in each combination, totaling a maximum of about 4.8 million areas. We also considered the case of focusing on three dimensions, as shown in
Figure 11b. We considered the 620,620 combinations of selecting three from all 156 financial items. Therefore, it is necessary to calculate the existence probability of data satisfying specific conditions in a maximum of 8000 areas in each combination, totaling a maximum of about 3 billion areas. Thus, the computational cost increases exponentially as we increase the number of dimensions that we begin to focus on. Therefore, we consider this method of addressing this problem when only a few variables exist. However, even if we searched exhaustively for a specific dimension, the same problem can occur above that dimension and beyond. Specifically,
Figure 11b shows an example where a miss occurs in some three-dimensional areas, regardless of whether one starts looking at a one-dimensional or two-dimensional area. Therefore, we must discuss which dimension to examine exhaustively and which dimension and beyond to ignore invisible relationships.
We compared some popular existing methods with our method for comparison. In high-dimensional areas, when data satisfying specific conditions are concentrated in multiple areas, we call the problem of extracting all areas the multimodality problem. In the special case that there is only one highly concentrated area in the whole space, we call it a unimodality problem. For unimodality problems, we can extract the dense area by using popular methods such as multiple regression analysis or support vector machines. However, these methods are not suitable for the analysis of high-growth firms in this study, as we showed in
Section 4, there are at least 15 dense areas in the 156-dimensional space. In addition, other popular methods, neural networks [
33], are black-box methods, making it impossible to interpret the results in terms of important financial items. Random forests are also popular in big data analysis; however, they are unsuitable for the present problem of extracting important factors in the form of sets of variables. Our method can extract the sets of important factors for multimodality problems and is suitable for the analysis of high-growth firms.
We also compared the factors extracted in this study to Coad’s previous study [
28]. In that study, they used cluster analysis, which is strong for multimodality problems, to analyze the important factors of high-growth firms. Although the high-growth firms in the previous study are about 2% of the total data, we note that the definitions of high-growth firms and the variables used are very different. The previous study found that firms with low inventories, higher previous employment growth, and higher short-term liabilities are more likely considered high-growth firms. As previous employment growth is excluded from the financial item of this study, we analyzed other results. We identified the factor of low inventory as a universal factor in Group ⑩ and Group ⑭ of this study (see
Figure 9 and
Table 11). We extracted the factor of higher short-term liabilities in the high-dimensional area of
Table 9. Therefore, we can assume that we have extracted the same results as in the previous studies.
We also compared the factors extracted in this study to that of Delemar’s previous study [
26]. In that study, they used Lasso, which is strong for unimodality problems, to analyze the important factors involved in forecasting high-growth firms. We note that the definition of high-growth firms differs from the previous study and the variables used are also very different. After comparing the results with this assumption, we extracted similar results to the previous study for increasing employment. In the previous study, increasing employment was part of the factors for the seven clusters of high-growth firms. The firms in Group ⑭ in this study are financially robust and have increased their operating efficiency by making capital investments, developing human resources, and increasing employment. Therefore, we believe that the result extracted in this study is similar to the previous one. The previous study focused on revenue growth. However, in this study, we extracted the areas that focused on this as localized areas, with the number of high-growth firms being less than 100 in any two-dimensional ones. The study was different from previous studies that extracted revenue growth as universal.
Finally, we analyzed the indicators used in our method. For the 15 groups extracted using our method, we found the poor operating efficiency for most groups. The possible reason is that we used the top 1% of all firms in sales growth rate as the definition of high-growth firms. Firms with approximately four times or higher sales after three years often have either a pattern; that is, firms with poor operating efficiency have succeeded in improving their sales or sales are small from the start. Thus, we may need to change the definition of high-growth firms. In addition, we measured firm growth in this study using the absolute one in sales over three years. As sales are not a perfect indicator [
26], some studies used the number of employees [
21,
34] and both the number of employees and sales [
35]. Therefore, discussing which items we should use as a measure of growth and what should be the definition of a high-growing firm is necessary.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}